의료AI연구 — 후향적 연구와 전향적 연구의 괴리
3~4년 전만해도 이세돌이 알파고에게 패배한 것처럼 인공지능 연구를 하면 전문가를 대체하고 세상의 모든일을 대체할 것 같은 분위기였다. IEEE Spectrum 에 “AI versus Doctor” 라고 전문 분야별로 AI 와 Doctor 의 대결을 보여주는 기사 (https://ieeexplore.ieee.org/document/8048826)에서 의학 영역에서 AI 의 성과를 하나둘 기록했었다.
하지만, 1~2년 전부터는 인공지능이 전문가를 보조하는 역할에 대한 이야기가 주가 되고, 최근에는 인공지능으로 비즈니스에서 이익을 못낸다는 이야기도 심심치 않게 들린다. 심지어 IBM 의 왓슨은 비판과 함께 매각되기도 했다. 어떤 점에서 문제가 있었기에 이런 소식이 들리는 것일까?
2018 년에 우리 그룹은 무좀 진단에서 피부과 전문의를 압도하는 성능을 보인다는 결과를 냈다. 당시 IEEE Spectrum 에서도 기사 (https://spectrum.ieee.org/ai-beats-dermatologists-in-diagnosing-nail-fungus) 가 나갔다. 제목이 “AI Beats Dermatologists in Diagnosing Nail Fungus” 인 것처럼 AI 가 모든 분야에서 압도할 것 같은 당시의 분위기를 보여주는 제목이다.


위와 같은 손발톱 사진을 보고 무좀인지 아닌지 맞추는 퀴즈 (reader test) 를 진행했다. 위 그래프는 당시 논문에 나갔던 그래프인데, 참여했던 40여명의 피부과 의사 중에 AI 보다 잘한 의사는 한명도 없었다. 이 결과는 당시 무좀 진단에 경험이 많은, 무좀이 전공이신 전국 최고의 피부과 교수님들만으로 테스트했던 결과였다. 여기까지만 보면 2018년에 AI가 의료를 금방 정복할 것 같은 당시 모습과 동일하다.
하지만, 이러한 압도적인 결과는 사진을 보고 맞는지 테스트하는 “퀴즈쇼”의 결과이다. AI 를 의료 현장에서 직접 사용했을 때 AI 의 결과가 재현되어야 한다. 이러한 연구를 전향적 연구 (prospective study) 라고 한다. 우리는 2019 년에 무좀 알고리즘으로 전향적 연구 (https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0234334) 를 실시하였고 아래와 같은 결과를 얻었다.

대략 그래프에서 AI 의 성능은 참여한 전문의와 동일한 수준이었다. 다만 이 때 참가한 전문의는 무좀 전문의가 아니고 임상 강사였다. 후향적 연구(retrospective study)에서 최고 수준의 전문의를 압도했지만, 실제 성능은 일반 전문의와 동등한 수준이었다.
문제는 손발톱 무좀 진단이라는 주제가 AI 에게 매우 유리한 주제라는 점이다. 손발톱 사진은 구도를 통일하기가 매우 용이하다. 또한 다양한 진단 (multi-class classification) 이 아닌, 이분법적인 진단 (무좀 or 무좀 아님; binary classification) 만 내리면 된다. 게다가 무좀 모델은 이미 2 class 문제에 대해 여러번 검토된 5만여장의 이미지로 학습되었다. 모델을 개선하거나 이미지를 더 추가한다고 해서 크게 성능이 나아지기 힘든 상황이었다. 이 결과를 받아들고 나서 의료 영역에서 AI 의 전향적 성능이 녹녹치 않겠다는 판단을 하게 되었다.
2018 년에 우리는 12개 피부종양의 분류를 피부과 의사 수준으로 할 수 있다는 결과를 냈다 (http://www.jidonline.org/article/S0022-202X(18)30111-8/fulltext). 하지만 곧바로 실제 모델의 성능이 그런 수준이 아니라는 반박 letter 가 실렸다 (https://www.jidonline.org/article/S0022-202X(18)31991-2/fulltext). 이런 논란이 오갔던 것처럼 AI 가 퀴즈를 맞추는 부분에서 의사 수준인 것은 잘하는 것은 맞지만, 다른 사람이 같은 알고리즘 DEMO를 진료에서 직접 사용해 보면 그 성능이 기대보다 한참 못 미친다. 그렇다면 이 격차가 어느정도인 것일까?
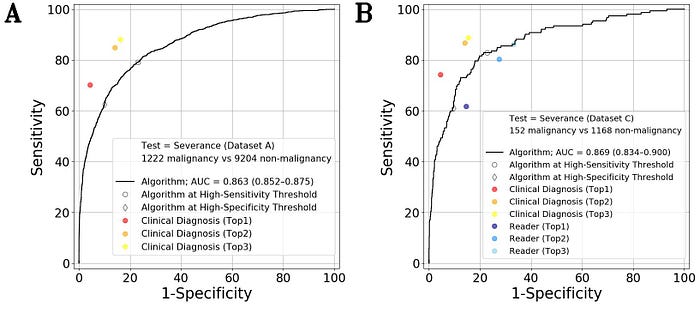
위 결과 (https://journals.plos.org/plosmedicine/article?id=10.1371/journal.pmed.1003381) 는 퀴즈쇼에서 잘하는 AI 가 왜 실제 진료 상황에서 시원치 않은지를 보여주는 결과이다. 결론부터 이야기하면 의사는 “퀴즈쇼”에서 보이는 진단 능력보다 훨씬 더 나은 진단 능력을 “실제 진료”에서 보인다. 위 그래프에서 같은 특이도(specificity)에서 사진만 보고 진단한 전문의보다 거의 25% 이상 더 높은 민감도(sensitivity)를 실제 진료 (in-person examination) 한 의사가 보인다. 이 연구를 할 당시에 퀴즈에 참여했던 임상 강사의 진단율이 너무 낮아서, 처음에는 성실하게 풀지 않아서 그런 것으로 생각하고, 같은 문제지를 3번 다시 푼 참여자도 있었다. 결론적으로 보면 사진만 보고 진단을 맞추는 일은 어느 피부과 전문의가 하더라도 잘 할 수 없다.
이 결과는 현재 후향적 연구(retrospective study) 위주로 실시되는 AI 연구의 결과가 쉽게 과장될 수 있다는 것을 보여준다. 실제로 한 리뷰 연구(https://www.thelancet.com/journals/landig/article/PIIS2589-7500(19)30123-2/fulltext) 에서 2만여개의 AI 연구 중에 전향적 연구(prospective study)는 20여개 밖에 안되는 현실을 지적했었다.
그렇다면 피부과 영역에서 AI 의 실제 성능은 어느정도일까? 이에 대해 우리는 전향적 연구 (prospective study) 를 최근에 실시하였다. 후향적 연구 결과에서 (a) 134 개 질환을 맞추는 문제 (multi-class) (b) 암인지 아닌지 판단하는 문제 (binary) 에 대해서 모두 대학 병원의 탑클래스 전문의 수준인 알고리즘이 사용되었다.
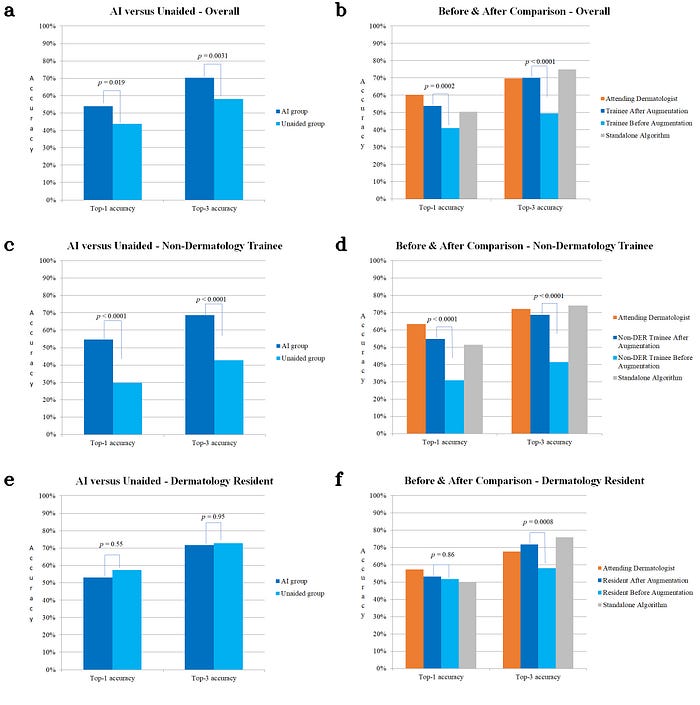
전향적으로 실시된 Randomized Controlled Study (RCT Study; https://www.jidonline.org/article/S0022-202X(22)00122-1/fulltext) 의 결과를 보면, AI 의 실제 성능은 Top-1 진단 (제시한 첫번째 진단이 정답이 확률)은 피부과 전공의 1년차 수준이었고, Top-3 진단 (제시한 3개 진단내에 정답이 있을 확률) 은 피부과 전문의 수준이었다. 먼저 이야기 한것처럼 사용된 알고리즘의 후향적 성능은 탑클라스 피부과 전문의 수준이었다는 것을 감안하면, 이는 한 단계 떨어지는 결과이다.
이 연구에서 AI 의 단독 성능만 보지 않고 AI 가 의사의 진단율을 올릴 수 있느냐도 보았다. 결과는 인턴 선생님처럼 피부과 지식이 전혀 없는 경우 진단의 정확도가 많이 향상되었지만, 1년차 전공의처럼 피부과 지식이 어느정도 있는 경우 진단의 정확도가 향상되지 않았다. 다만 Top-3 진단 능력은 AI 가 전문의 수준이고 1년차 전공의보다 우수했기 때문에, Top-3 진단 부분은 AI 가 1년차 전공의의 진단 능력을 향상시켜 줄 수 있었다. 즉, AI 가 전향적인 테스트에서 유저보다 성능이 좋은 경우에만 도움을 주었다.
후향적인 연구에서 AI 가 강점을 보이지만 전향적인 환경에서 같은 모습을 보이지 못하는 다양한 이유가 있다. (a) 실제 진료보는 의사 (in-person examination)는 훨씬 더 정확하고, (b) Clever-Han type bias 와 같이 치팅에 의해 벤치마크 결과만 좋을 수 있고, (c) OOD (out-of-distribution) 문제처럼 학습되지 않은 문제를 전혀 맞추지 못하는 문제가 있다.
AI 는 예측 (prediction) 을 위해 존재한다. 그런데, 과거의 결과만 잘 맞춰서는 쓸 수 있는 곳이 없다. 전통적인 통계 결과는 후향적 데이터를 분석해서 bias 가 있더라도 insight 를 얻을 수 있지만, AI 연구 결과물에는 이런 부분을 찾을 수 없다. 반드시 전향적 데이터를 잘 예측할 수 있어야 한다. 의료 AI 연구에서 전향적인 성능과 후향적인 성능에 많은 차이가 있기 때문에, 특히 변수가 많은 주제의 경우 후향적 데이터 결과를 그대로 신뢰하기 어렵다.
향후 이러한 문제를 극복하기 위해서는 첫번째, AI 가 잘 할 수 있는 문제로 범위를 좁히고 선택하는 것이 중요하다. 손발톱 무좀은 질환 자체로 보았을때는 해외 에디터가 보기에 하나도 중요하지 않은 문제이다. (의학잡지 에디터에게 손발톱 무좀 연구는 발에 낀 때를 연구하는 것과 비슷한 급이다. 해외에서는 무좀은 병이라기 보다는 불편한 문제다.) 하지만, 배경이 일정하고, 구도를 쉽게 통일할 수 있고, 인종 차이가 없고, 많은 data 를 얻을 수 있기 때문에 선택하였다. AI 가 배경 이미지나 구도에 영향을 받는다는 이런 사실을 논문에는 큰 언급이 없더라도 실제 사용해 본 사람들은 2017년에 이미 다들 체감한 문제였다. 비슷하게 구도를 통일해 줄 수 있는 문제 (입술 질환 — https://onlinelibrary.wiley.com/doi/abs/10.1111/bjd.19069)를 다루거나 성병처럼 부위나 질환을 통일해서 차원을 줄여줄 수 있는 문제 (https://mhealth.jmir.org/2020/11/e16517)를 생각해내서 선택하는 것이 나은 방향이다.
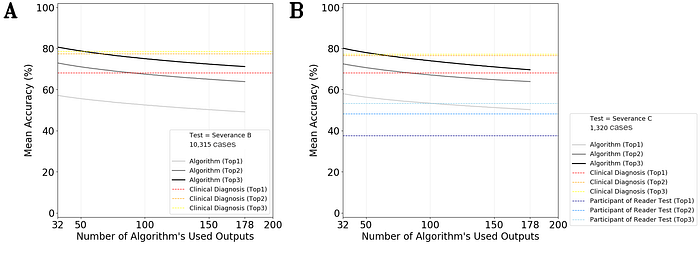
위 그래프는 문제의 차원(class)이 늘어날수록 알고리즘의 성능이 수렴하지 않고 linear 하게 떨어지는 것을 보여주는 그래프이다 (https://journals.plos.org/plosmedicine/article?id=10.1371/journal.pmed.1003381). 아주 완전히 모양이 다른 class 라도, 일단 class 가 늘어나면 예상보다 많은 data 가 필요한 것으로 추정된다. class 가 늘어나면 차원은 기하급수적으로 늘어나고, 비록 우리가 접하는 문제는 다차원의 일부영역에 한정된다 하더라도 이에 대응하려면 예상보다 많은 data 가 필요한 것 같다. 따라서 모든 OOD (out-of-distribution) condition 을 커버하는 것은 현재 기술과 데이터 수준으로 어려움이 있기 때문에, 적절히 문제의 범위를 좁혀서 접근해야 할 것으로 생각한다.
두번째는, 도메인지식인 의학지식을 이용해서 Data 를 잘 다룰 수 있어야 한다. Data Scientist 는 Tensorflow, PyTorch, Python 의 단순한 End-user 로 끝나서는 안된다. 기술적인 부분에 해박해서 위와 같은 Framework 를 직접 수정하고 발전시킬 수준이 아니라면, 일관성 있게 Data 생성을 관장할 수 있는 오케스트라의 지휘자 같은 역할을 해야 한다. 최근 AI 의 성능을 개선하기 위해 NVidia 처럼 synthetic data 를 생성하는 노력 (https://blogs.nvidia.com/blog/2021/06/08/what-is-synthetic-data/) 을 하거나 Andrew Ng 처럼 data 를 다듬는 노력(data-centric AI; https://spectrum.ieee.org/andrew-ng-data-centric-ai) 에 대한 언급이 자주되고 있다. 어떤 모델을 사용할지, 학습 파라메터를 어떻게 정하느냐와 같은 기술적인 개선으로는 성능을 증가시키는데 한계가 있다.
세번째는, 전향적인 연구 설계를 잘 하고 이를 통해 모델의 진단 특성에 대한 경험이 있어야 한다. 후향적 연구와 달리 전향적인 연구는 다양한 변수가 있기 때문에, 실수는 신뢰할 수 없는 결과를 내는 “꽝”으로 이어진다. AI 는 미래의 예측을 위해 존재한다. 소규모 연구라도 전향적인 연구를 반복해서 문제를 인식하고 개선하면서, 연구 설계 경험을 쌓고 동시에 모델의 특성을 파악하는 것이 중요하다.
요약하자면, AI 가 퀴즈를 잘 맞추는지 아닌지가 중요한 문제가 아니고, AI 가 의료 현장에서 잘 맞춰야 한다. 더 나아가 AI 가 의료진 또는 환자의 판단을 바꿀 수 있어야 한다. 추후에 이러한 판단의 변화가 생존률, 의료 비용등의 개선으로 이어져야 한다. 그러나 현재 전향적-후향적 연구 결과의 격차는 상당한 수준이기 때문에, 문제의 범위를 잘 좁히고 data 개선을 위해 피,땀,눈물을 흘리며 노력해야 한다.
REFERENCE — OUR WORKS
- Assessment of Deep Neural Networks for the Diagnosis of Benign and Malignant Skin Neoplasms in Comparison with Dermatologists: A Retrospective Validation Study. PLOS Medicine, 2020
- Performance of a deep neural network in teledermatology: a single‐center prospective diagnostic study. J Eur Acad Dermatol Venereol. 2020
- Keratinocytic Skin Cancer Detection on the Face using Region-based Convolutional Neural Network. JAMA Dermatol. 2019
- Seems to be low, but is it really poor? : Need for Cohort and Comparative studies to Clarify Performance of Deep Neural Networks. J Invest Dermatol. 2020
- Multiclass Artificial Intelligence in Dermatology: Progress but Still Room for Improvement. J Invest Dermatol. 2020
- Augment Intelligence Dermatology : Deep Neural Networks Empower Medical Professionals in Diagnosing Skin Cancer and Predicting Treatment Options for 134 Skin Disorders. J Invest Dermatol. 2020
- Interpretation of the Outputs of Deep Learning Model trained with Skin Cancer Dataset. J Invest Dermatol. 2018
- Automated Dermatological Diagnosis: Hype or Reality? J Invest Dermatol. 2018
- Classification of the Clinical Images for Benign and Malignant Cutaneous Tumors Using a Deep Learning Algorithm. J Invest Dermatol. 2018
- Augmenting the Accuracy of Trainee Doctors in Diagnosing Skin Lesions Suspected of Skin Neoplasms in a Real-World Setting: A Prospective Controlled Before and After Study. PLOS One, 2022
- Evaluation of Artificial Intelligence-assisted Diagnosis of Skin Neoplasms — a single-center, paralleled, unmasked, randomized controlled trial. J Invest Dermatol. 2022
